Evidence-based trials: better compared than randomized
Evidence-based trials: better compared than randomized
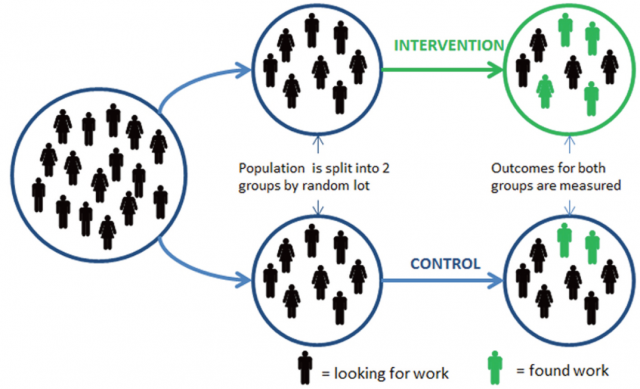
For quite a while now, it has been assumed that Randomized Controlled Trials (RCTs) have improved the way we acquire knowledge, especially in the scientific area where this technique is the gold standard, clinical practice. From Medicine to Social sciences, evidence-based policies 1 have turned into the widespread common ground from where to seek trustworthy information and also develop further discussion constructed on facts.
But what if, as according to a recent paper published on PLoS ONE by the statistics and computer sciences professor at Nordhausen University of Applied Sciences Dr. Uwe Saint-Mont 2, this approach was just too optimistic? Perhaps, he explains, the great advancement in this scientific methodology comes due to the comparability of these experiments rather than its randomization.
Acknowledging straightforwardly the value of RCTs as a model “proved to be a great success”, the author of the paper explains certain reservations with the procedure that require improvement. For instance, the fact that assigning random values to two totally different groups, without further control, might provoke in researchers a false sense of security and undetected bias.
Moreover, Saint-Mont states that scientists might even fail to realize that, as a result of the randomization, the imbalance between the two subjects of the test just happens to be the rule rather than the exception. Not to mention that this last scenario would not be counted as an outcome of the experiment ― on the contrary, it would be just somewhat of an undetected variable.
Following the account of these problems, Saint-Mont lists key ideas of a five-step-plan to try to avoid them effectively: the need of a good experimental practice and strict control based on random assignments to compare groups, being the scale of these large enough to prevent imbalances and unknown factors alike, and also the required capacity to analyse the obtained data afterwards to avoid weak conclusions.
That’s why the aim of this research, following R.A. Fisher’s steps as one of the most influential statistician of the 20th century and nevertheless broadening its teachings, is to attempt reducing the pre-existing differences between groups during an experiment in order to be able to obtain more reliable data. And of course focusing on reproducing them later in similar conditions ― a vital part of a clinical trial, yet one premise that has failed to be accomplished lately as lots of RCTs turned out to be non-replicable. So, in this setting, minimization is not just some additional technique to improve the efficiency of the experiment, whereas a direct and elaborate device to enhance its comparability.
As stated in the logic of the experiment section of the article, the evidence produced via randomized trials seems to be as consistent as the background knowledge of the analysed groups. The more complete the context and developed framework, the better the conclusions. In his final thoughts, Saint-Mont endorses adding more emphasis, without leaving behind traditional experimentation, to the process all along as a way to stimulate comparability and to avoid confusing results.
References
- L. Haynes, B. Goldacre & D. Torgerson (2012),Test, Learn, Adapt: Developing Public Policy with Randomized Controlled Trials, Cabinet Office-Behavioural Insights Team. ↩
- Saint-Mont, U. (2015), Randomization Does Not Help Much, Comparability Does. PLoS ONE 10(7): e0132102. DOI: 10.1371/journal.pone.0132102 ↩
1 comment
[…] Los experimentos con dos grupos aleatorios, uno de ellos de control, son la máxima expresión de la fiabilidad de los estudios con humanos, especialmente los clínicos. Pero, ¿y si la aleatoriedad no fuese lo importante? Jon Gurutz Izquierdo en […]