A starker p-value
A starker p-value
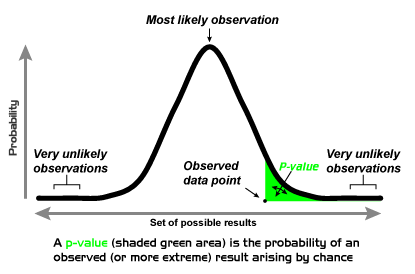
In science, for a phenomenon to be reliable, it needs to be validated by a certain statistical value, the p-value, which by giving an estimate of the probability that the result would be the product of chance, serves as a measure of the probability that a certain event happening is true. So far, the convention states that any result with a p-value<0.05 is already good scientific evidence. However, given the reproducibility crisis from the last years (scientists all over the world are failing to reproduce the results from other teams) and the number of false-positives (an effect claimed to be real but actually false) reported in scientific literature, a group of researchers has recently proposed to increase this statistical threshold to p<0.005, an order of magnitude smaller, thus aiming for higher stringency in the consideration of scientific data.
Even though the proponents of this change claim that by this change many false positives could be avoided and would make for better science, they still acknowledge that the p-value is nothing but a relatively arbitrary threshold that should be, ideally, combined with other types of evidence: such previous evidence of similar effects, etcetera.
As ever in science, there are diverging opinions, some scientists consider that even if a more stringent statistical threshold would do away with some “weak” science, the big problems of reproducibility: fishing for positive results from a number of hypothesis to test, or the positive publication bias (it is recognised that it is much easier to publish work proving something to be positive than to disprove that, for example, a drug doesn’t really produce the desired effect) would still remain. Moreover, to be able to achieve a p-value of p<0.005, clinical research would have to start increasing the number of patients involved, with the associated increased cost for clinical trials, that might result in a diminished interest of the pharmaceutical industry for R+D.
Be it as it may, the key point of the manuscript is that p<0.05 is a weak measure of effects in science, and it is important to raise awareness in this sense, that such a threshold might not be enough to claim a positive effect and/or grant publication.
Sources:
It will be much harder to call new findings ‘significant’ if this team gets its way. Kelly Service. Science News. 25 July 2017
Big names in statistics want to shake up much-maligned P value. Dalmeet Singh Chawla. Nature News. 27 July 2017
3 comments
Reproducibility depends on methodology, not p values.
The p value is defined in relation with the sample, with small samples (as in medicine), a smaller p value threshold will of course reduce the false positives, but increasing the false negatives.
Well, the thing is that it is not that clear we are facing a reproducibility crisis:
http://francis.naukas.com/2018/03/17/la-leyenda-de-la-crisis-de-la-reproducibilidad-cientifica/
and references mentioned there, particularly the PNAS issue devoted to this.
[…] Keep on reading on Mappingignorance.org […]