Reinforcement learning in the brain
Reinforcement learning in the brain
The term reinforcement learning is well known among researchers in the areas of machine learning and artificial intelligence. It refers to a type of algorithms which are designed to solve a task by maximizing some kind of reward. In a simplified way, we could say that a typical reinforcement learning algorithm works as follows: our system makes an attempt to solve the problem (say, to discern between pictures of human faces or cat faces), and then it gets a reward based on its performance. Later, the algorithm modifies the system’s parameters depending on the reward obtained, and attempts to solve the task again. By means of this slow modification of the parameters, the system becomes more and more efficient solving the task, and eventually we will have a – hopefully – excellent classifier of human or cat faces.
The idea for this type of algorithms came from the field of behaviorist psychology, and one can clearly see influences from Thorndike’s law of effect – i.e. that the behavior associated with a pleasant reward is more likely to occur again 1. A clear example is the way we educate our pets or train them to do tricks: we try to establish an association for the pet between the trick or good habit and some convenient reward (say, a cookie). In spite of a large number of behavioral studies, not much is known about how reinforcement learning is carried out in the brain, or what kind of circuits could be important for it (although basal ganglia has been identified as a potential area in which reinforcement learning might occur, see 2).

Let’s think on a very simple discrimination task, where a neural network receives a certain stimulus and it has to make a choice between two possible responses: A and B. This could represent, in an extremely simplified way, a decision-making process (“Is this a human face or a cat face?”). The most simple decision-making mechanism in a neural network that we can think of is an activity-threshold mechanism: if the average activity of the neural network surpasses a certain threshold (as a consequence of the stimulus), then the chosen answer is A, otherwise it is B. After the decision, the network receives the environmental reward, which should ideally trigger neural plasticity mechanisms and improve the performance of the neural network – and the individual – in future decision-making processes.
A fundamental problem, however, stands in the way of understanding reinforcement learning in the brain: the reward is typically presented at the behavioral or environmental level (food, or a pleasant stimulus, or a “thank you”) and therefore macroscopic, while the mechanisms and structures that have to be modified based on the reward (such as neurons and synapses) are microscopic.
Where is exactly the problem? As we mentioned before, the reward is assumed to drive the changes in our neural network, via plasticity mechanisms, in order to maximize the reward in future attempts. But an environmental-level reward is way too vague to constitute a meaningful piece of information for a single neuron in the network. Indeed, as the number of neurons in our network increases, the activity of any single neuron has less and less impact on the overall network activity, and the macroscopic reward (which depends purely on the overall activity of the network) will be less and less related to this single neuron’s activity.
Consider for instance, in the previous example, the situation in which the average response of the network was A, and the reward is negative (or there is no reward, for the matter). This means that the decision was wrong, but the negative reward would punish the neurons which fired (and therefore contributed to choose A) and the neurons which remained silent (and were therefore contributing to choose B). A neuron which decided not to fire in this task, therefore, is being punished by a mistake that it did not make. The situation would be analogous to having a class of students take an exam and only telling them whether the majority of the class passed or failed, instead of giving the individual results to each student. Obviously, this information would be of little use to the students (which would keep making the same mistakes in the following exams). And the larger the number of students in the class is, the more useless this information is, and the lower the overall performance of the class would be.
Putting aside the class of unfortunate students with an evil teacher, the problem of how an environmental reward can efficiently trigger changes at the microscopic level in a neural network, leading to an effective reinforcement learning, has been partially solved by researchers in the University of Bern in Switzerland 3. The researchers, using a mathematical model which resembles the example of the decision-making task explained above, have found a way to infer microscopic rewards (aimed at single neurons) from the macroscopic, environmental reward. Or, in other words, the students can now estimate their individual grades even without the help of the evil teacher.
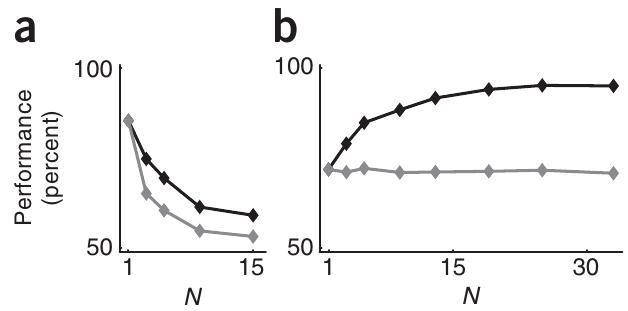
In order for this mechanism to work, each neuron needs to have the information about the decision taken by the network (that is, the overall network activity) and the reward associated with such a decision. These two ingredients can actually be known by the neuron, since they are encoded in ambient neurotransmitter levels surrounding the neurons (for instance, in the dopamine ambient concentration level). A third, secret ingredient is needed: the neuron has to keep track of its recent activity. This condition can also be easily fulfilled in real neural networks, since the neuron’s own calcium dynamics or other long-decaying mechanisms are able to provide some level of “memory” to the individual neuron’s dynamics. With these three ingredients, the overall performance of the network increases with the number of neurons in the network (instead of decreasing as with our previous models of reinforcement learning). Interestingly, even though the performance of any individual neuron is constant, the overall performance of the system improves with the number of neurons, suggesting that the improvement is an emergent property of the system due to the cooperation of many neurons.
These results, although of purely theoretical nature, could be very relevant to understand the basis of reinforcement learning in the brain, by suggesting new experimental tests for this theoretical framework and providing guidance to other researchers.
References
- Wikipedia: Law of effect. http://en.wikipedia.org/wiki/Law_of_effect ↩
- I. Bar-Gad, G. Morris, and H. Bergman, Information processing, dimensionality reduction and reinforcement learning in the basal ganglia. Prog. Neurobiol., 71, 439-473, 2003. ↩
- R. Urbanczik, and W. Senn, Reinforcement learning in populations of spiking neurons. Nature Neuroscience, 12, 250-252, 2009. ↩
7 comments
Well, great article. Then insist that learning improves learning but is there a limit to the neural network learning retries?
Is there any connection with the idea that language capacity provide us room to become intelligent and the more intelligent we are the better language we perform?… I think that is the key question to understand essentials differences between the human been and other type of animals…
@Miguel Pelaez: This is indeed an interesting thought. Language, as an effective way of communicate with others, would provide some kind of “social reward”. It is then possible that reinforcement learning mechanisms are partially responsible for this good feeling we have when we are able to communicate with others (just think about the first time you realized you were actually able to talk with people in another language).
Although the acquisition of language is much more complex than that and would be material for, at least, another post 🙂
@Phoenix_alx: Thanks! In principle, the neural network can undergo as many learning retries as you want, there is no limit there. However, the network will reach some equilibrium level after enough training.
In the case of one neuron in the new model, this equilibrium level is around 70% (see fig 2b for N=1), and to improve that you need to increase N. More training wouldn’t have any effect.
Me resulta curioso cómo un físico habla de fisiología. Te expresas de forma diferente a como lo haría alguien de la rama biosanitaria.
😛
¡Gracias! La idea es precisamente potenciar la interacción con investigadores de ramas biosanitarias (con experimentos basados en las predicciones del modelo, por ejemplo), para conseguir que sea realmente algo multidisciplinar y no solo el punto de vista de un físico 🙂
I’m curious where Paloma sees the funny speech. I read the text quite in tone with current neuroscience journals. Perhaps I’m too used myself to this kind of approach, in spite moving mostly on Physiology/Pharmacology topics.
I’m serious that a bit more explanation about the perceived differences would be insteresting.