Raw Science: The DNA ladder (1977)
Raw Science: The DNA ladder (1977)
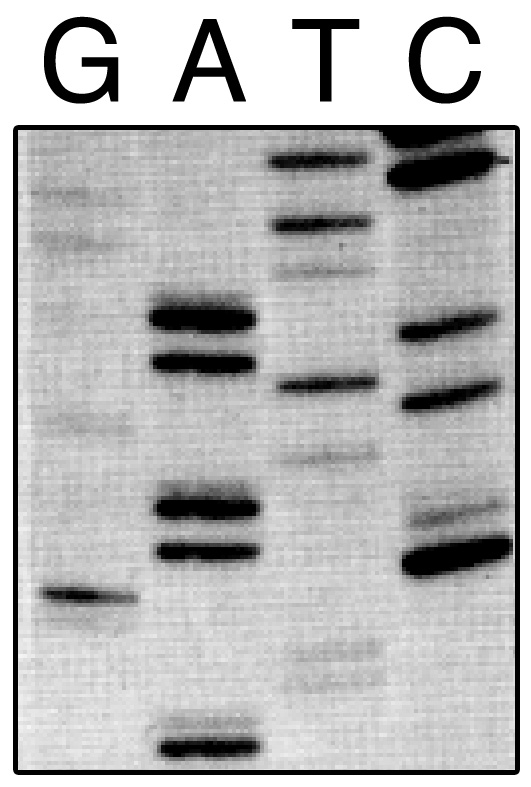
Can you guess the sequence of the DNA strand that is analyzed in this experiment? (Feel free to use the comments!). One does not need to be a biochemist to figure it out. Start from the bottom of the picture. Just jump from one step of the “ladder” to the next, even if it is in another lane and note the letter of the nucleotide (The DNA building blocks: G,A,T or C) that is shown above that lane. To give you a hint: the first two are AA (the second A is pretty weak), then TT (with a really weak signal). Can you guess the whole sequence? AATTG….
You are analyzing the original Sanger’s DNA sequencing experiment published in 1977, an innovative method to easily determine the sequence of DNA strands. This idea granted Frederick Sanger his second Nobel Prize and began the revolution of our time: the era of genomics.
Each lane of this experiment is the result of a separate reaction in which a DNA strand serves as template and it is copied multiple times by the DNA polymerase. One of four different specific drugs that mimic each of the four nucleotides G,A,T,C were added to either reaction experiment. Each drug stops the copying of the strand when entering it. Because the drug concentration is really low most of the copies reach the end without stopping, but others stop at different points: whenever that specific nucleotide is required, like an empty ink cartridge stops a printing machine only when that colour is needed. DNA copies of all possible different lengths are generated after hundreds of reactions. They are easily separated by length in a soft matrix under an electric current (a method well known at the time). This soft matrix, with the four different reactions, is what you were analyzing before.
This method was unbeatable for over 30 years: It was used for sequencing the first human genome and it is the principle behind most of the DNA technology used in current laboratories. If you read any article about something related to DNA there is almost a 100% chance that those scientists relied on Sanger’s sequencing method at some point.
2 comments
I have a doubt:
AATTGGCACAATG¿G?CTACAATGTGCTC
I think the correct sequence is:
AATTGGCACAATGGCTACAATGTGCTC
That’s a pretty complicated one, I had to check it in the original manuscript. It is just one G (CAATGC) but it looks like two. When there 2 in a row AND they are so weak one can see the space between them (see the 2 Ts at the bottom). At this part of the DNA gel (the matrix) they only look so close when one or both are really saturated (see the Lane A).