Deep learning
Deep learning

Artificial intelligence (AI) is one of the most actives fields of computer science. The idea of a computer learning, in an autonomous way, complicate tasks is exciting from both the fundamental and applied points of view.
One very recent and interesting approach to this problem is Deep Learning 1. This technology is becoming popular very fast and cutting-edge technological companies as Google, Microsoft and Apple are using it currently for speech and image recognition. Last November a paper in the main page of New York Times 2 introduced this new technology to the common public. This article includes an interview to the main developer of this technique, Dr Hinton, who concluded: “The point about this approach is that it scales beautifully. Basically you just need to keep making it bigger and faster, and it will get better. There’s no looking back now.”

So let discuss what is new about this new approach and why it is interesting. First, the problem its tries to deal with is the problem of recognition. This is a fundamental and complicate problem. For human beings is really easy to create categories in order to classify different abstract concepts as “cat” or “dog”. Once the categories are created, to recognize if an object belong to one of them is again not complicate. For an AI program this is a formidable task.
One of the key concepts of deep learning is the different levels of representations. If we want to classify a picture, as is shown in Figure 1, we should start with the low level representation, which is the pixels that compose the picture. On the other hand, as this level is not the desired one, we really want to increase the level of abstraction until we reach an abstract classification of our picture.
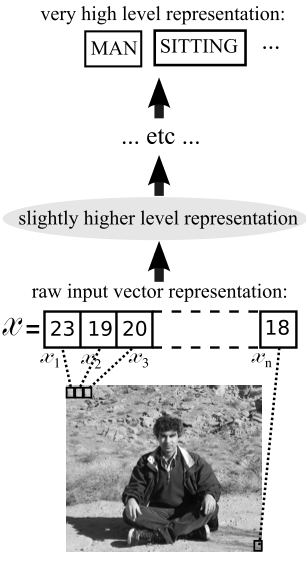
This concept makes clear the fact that for classifying different objects into abstract categories the level of abstraction should increase progressively. That was the method used by Hinton and his group in order to create a algorithm able of classifying a large set of High Resolution (HR) pictures with a small probability of error.
In their work, Hinton et al trained a deep neural network composed by eight different layers, each of one representing different levels of abstraction. This network was the winner of the top-5 test of the Large Scale Visual Recognition Challenge 2012 (ILSVRC2012). The rules of this competition were:
-
The goal was to classify the 15 million HR images from ImageNet .
-
For training the set 1.2 million images were used.
-
The pictures were classified in 1000 categories.
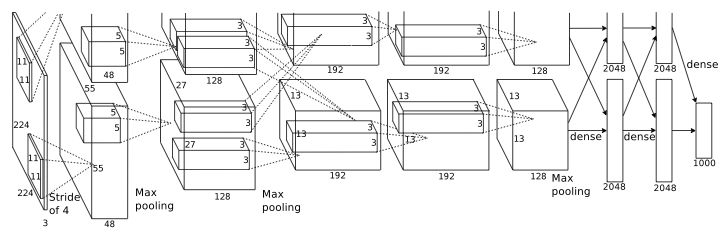
The network was composed of 8 layers, see Figure 4, with a progressive reduction of the number of neurons in each layer. The first layer’s input is the picture to classify and the last one has only 1000 neurons. The output of these last neurons determines in which category is the picture classified. The network used GPU’s parallelization and it took several days in finishing the learning procedure.
In the top-5 test the goal is to correctly classify the picture by the 5 most probable options. In figure 5 some classifications are displayed.

In this category this deep network achieved an error rate of 15.3%, compared of the 26.2% achieved by the second best architecture. For the top-1 test, that is classifying the pictures with only one guess, the error ratio was 37.5%.
Deep Learning has been proved as a very useful technique for image recognition. Even an error rate of 37.5% for first guesses is very difficult to accomplish, considering that there are 15 million HR images and 1000 categories. Furthermore, as Hinton said in The New York Times, this technique scales properly with the resources, so just by increasing the computational power the error rate should reduce. The potential applications are unlimited.
References
- Y. Bengio. “Learning Deep Architectures for AI”. Foundations & Trends in Machine Learning 2, 1 (2009). ↩
- J. Markoff “Scientists See Promise in Deep-Learning Programs“. The New York Times 23/11/2012. ↩
3 comments
[…] submitted by yself [link] […]
[…] results have been announced recently. One of the critical advances in this field is the capacity of recognising images. This line has led to technologies such as self-driving cars. There are many other recent […]
[…] results have been announced recently. One of the critical advances in this field is the capacity of recognising images. This line has led to technologies such as self-driving cars. There are many other recent […]